[한.권.컴.구] Ch1. 컴퓨터 내부의 언어 체계

0. 들어가며
P34 자바는 부분적으로 당시 널리 쓰였던 C 프로그래밍 언어를 본떠 만들어졌다. C에는 메모리 자동 관리가 없었고, 메모리 관리 오류는 당시 프로그래머에게 자주 두통을 일으키게 하는 오류였다. 자바는 언어 설계를 통해 이러한 종류의 오류(메모리 관리 관련 오류)를 없앴다. 이것이 자바가 초보자에게 좋은 언어가 된 이유 중 하나다.
하지만 좋은 프로그래머와 좋은 프로그램을 탄생시키려면 좋은 프로그래밍 언어 이상의 것이 필요하다. 그리고 자바로 인해, 디버깅하기 더 어려운 새로운 버그 종류가 생겨났음이 드러났다. 이런 버그 중에는 감춰진 메모리 관리 시스템으로 인해 생긴 형편없는 성능이 포함된다.
P36 요즘 프로그래밍은 미디를 사용하는 것처럼 되고 있다. 더 이상 프로그램을 작성하기 위해 여러 해 동안 연습을 하거나 이론을 배우지 않는다. 하지만 그렇다고 해서, 이런 식으로 작성된 프로그램이 좋은 프로그램이거나 신뢰할 만한 프로그램인 것은 아니다.
P37 울프람은 컴퓨팅 사고를 “컴퓨터가 할 일을 지시하기 위해 충분히 명확하게, 충분히 시스템적으로 사물을 수식화하는 방법”이라고 정의했다. … 하부 기술을 잘 이해하면 무엇이 잘못되고 있는지 알아차리는 능력을 계발할 수 있다. 고수준 도구만 알면 잘못된 질문을 던지기 쉽다. 전동 공구를 사용하려면 먼저 망치 쓰는 법부터 익혀야 한다. 하부 시스템과 도구를 배워둬야 하는 또 다른 이유는 이를 통해 여러분이 새로운 도구를 만들 수 있는 능력을 가질 수 있다는 점이다. 새로운 도구를 만드는 사람은 언제나 필요하며, 도구 사용자가 늘어나면 늘어날수록 이런 사람의 중요성은 더 커진다.
P38 좋은 프로그래머는 어떤 프로그래머일까? 첫 번째이자 가장 중요한 것으로, 좋은 프로그래머는 좋은 비판적 사고와 분석 기술을 지녀야 한다. 복잡한 문제를 해결하기 위해 프로그래머는 프로그램이 올바른 문제를 제대로 해결하는지 판단할 능력을 갖춰야 한다. … 좋은 프로그래머는 컴퓨터 작동을 잘 이해해야 한다. 기반 지식이 얕으면 복잡한 문제를 잘 풀 수 없다.
P39 컴퓨터 프로그래밍은 두 단계로 이뤄진다.
- 우주를 이해한다.
- 3살짜리 아이에게 이해한 내용을 설명한다.
이 말이 무슨 뜻일까? 컴퓨터 프로그램을 사용해 여러분 스스로도 이해하지 못하는 일을 할 수는 없다. 예를 들어 철자법을 모른다면 철자 교정 프로그램을 작성할 수 없고, 물리를 모르면 좋은 액션은 액션 비디오 게임을 만들 수 없다. 따라서 좋은 컴퓨터 프로그래머가 되기 위한 첫 번째 단계는 모든 분야를 가능한 많이 배우는 것이다. 문제에 대한 해답을 종종 예기치 못한 장소에서 발견할 수 있다. 따라서 어떤 것이 당장 필요하지는 않을 것이라며 무시해서는 안 된다.
P41 요컨대, 컴퓨터 프로그래밍이란 여러분이 문제를 풀기 위해 알아야 할 필요가 있는 내용을 배우고, 이 내용을 어린아이에게 설명하는 과정이다. 문제를 푸는 방법이 여러 가지이기 때문에 프로그래밍은 과학이자 기술이다.
인간이 무의식중에 작업을 해낼 수 있는 엄청난 능력은 프로그래밍을 하는 방법을 배우는 것을 더 힘들게 한다. 프로그래밍은 작업을 컴퓨터가 따라 할 수 있는 더 작은 단계로 분해해야 하기 때문이다. … 여러분이 만든 규칙은 얼마나 뛰어날까? 여러분이 빠트린 부분은 무엇일까? 게임을 플레이할 때 여러분이 어떤 식으로 판단을 내리는지 정말로 알고 있는가? 직관적으로 알고 있기 때문에 목록에 굳이 적지 않은 요인이 꽤 많을 가능성이 높다. 문제를 분명히 이해하지 못했다면, 첫 단계인 ‘우주를 이해하라’가 두 번째 단계인 ‘3살짜리 아이에게 설명하라’보다 훨씬 더 중요하다. 생각해보라. 말할 내용이 없다면 말 잘하는 방법을 배운들 뭐가 좋겠는가?
코더, 프로그래머, 엔지니어, 컴퓨터과학자의 차이는 다음과 같다.
- 코더 : 코딩은 어느 정도의 기계적인 변환 작업을 의미한다. 예를 들어 의사가 ‘소한테 받혔음’이라는 진단을 보내오면 W55.2XA라는 코드를 할당할 수 있는 사람이다.
- 프로그래머 : 프로그래밍은 한 전문 분야 이상을 아는 사람을 의미한다. 마치 의사가 환자를 진찰하고 진단을 내리는 행위와 비슷하다.
- 엔지니어 : 일반적으로 엔지니어링은 지식을 얻고, 얻은 지식을 활용해 어떤 목표를 달성하는 기술이다. 예를 들면 의사나 간호사가 설명서를 읽지 않고도 5분 안에 사용할 수 있는 모니터링 시스템을 만드는 일을 하는 사람이다.
- 컴퓨터과학자 : 컴퓨터 과학은 계산에 대해 연구하는 학문이다. 컴퓨터과학에서 발견한 내용을 엔지니어와 프로그래머가 사용한다.
컴퓨터 과학을 시각화 하면 다음과 같다.
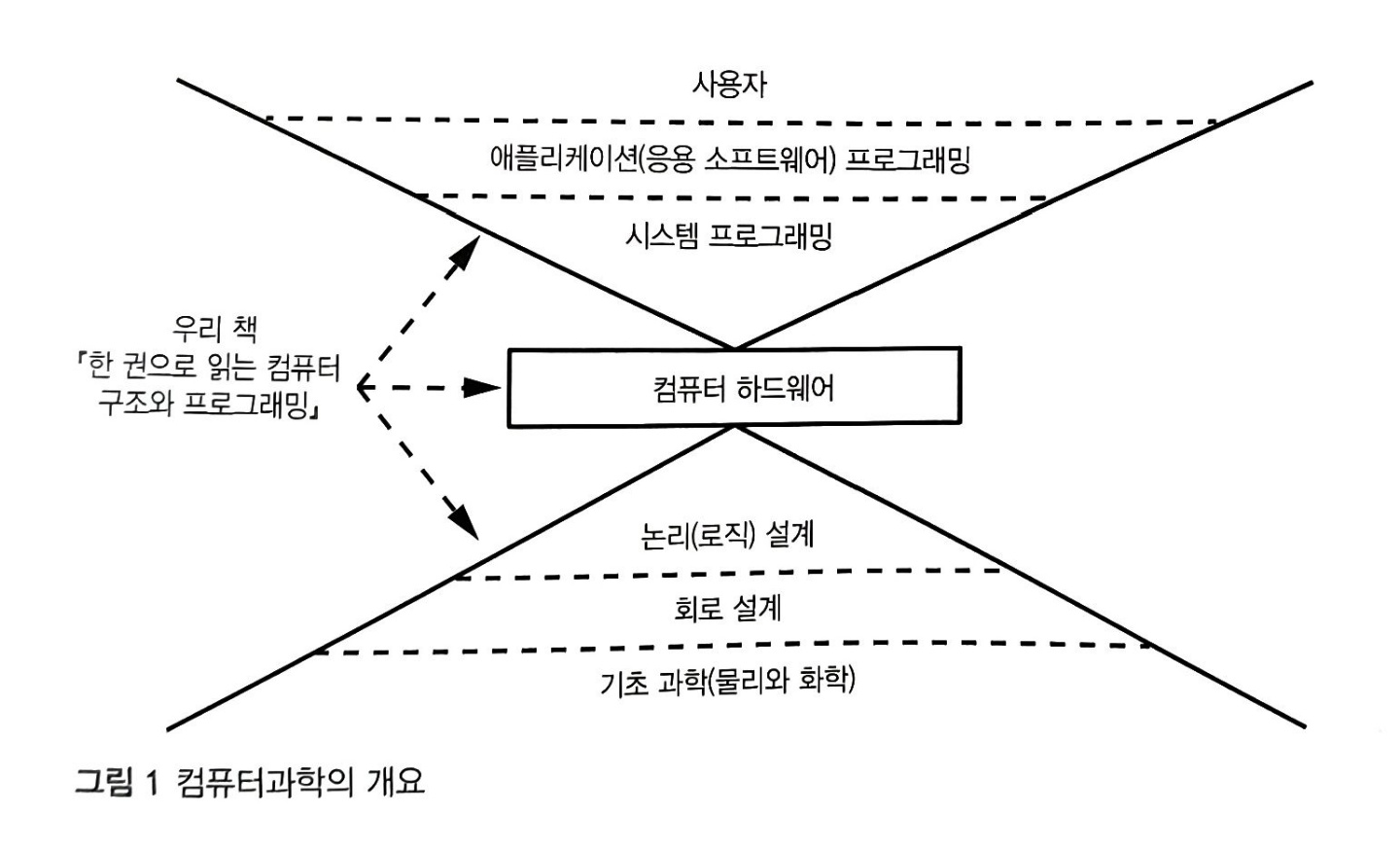
이 책에서 다루는 부분은 시스템 프로그래밍, 컴퓨터 하드웨어, 그리고 논리 설계이다. 시스템 프로그래밍은 어플리케이션 프로그래머가 사용하는 기본 요소를 만든다. 시스템 프로그래머는 자신이 작성하는 코드가 하드웨어와 상호작용해야 하기 때문에 하드웨어에 대해 알아야만 한다. 컴퓨터 하드웨어에는 계산에 필요한 부품만 있는게 아니라, 외부 세계와 연결하기 위한 부품도 있다. 컴퓨터 하드웨어는 논리로 표현된다. 이 논리는 컴퓨터 프로그램을 작성할 때 사용되는 논리로 표현된다. 이 논리는 컴퓨터 프로그램을 작성할 때 사용하는 논리와 같다. 컴퓨터의 동작을 이해하려면 논리가 핵심이다.
그림 1의 다른 계층에서 일하고 싶다면 시스템 프로그래밍을 배우지 않아도 된다. 하지만 시스템 프로그래밍을 배우지 않는다면, 여러분의 도메인(전문 분야)을 벗어나는 문제가 생기면 문제를 직접 해결하려고 파고들기보다는 여러분을 도와줄 사람을 찾는 편이 더 낫다. 핵심 기술을 이해하면 높은 수준에서 더 나은 해법을 생각해 낼 수 있다.
1. 컴퓨터 내부의 언어 체계
컴퓨터는 어떤 말을 사용할까?
기본적으로 쉬운 내용들이 많아서 조금 살펴볼 만한 내용들 위주로 정리를 해 보려고 한다.
실수를 표현하는 방법
부동소수점 표현법
플랑크 상수부터 아보가드로 수에 이르는 범위의 값을 2진수로 표현한다는 문제를 해결하기 위해, 과학적 표기법(scientific notation)을 2진수에 적용한다. 과학적 표기법은 수를 해석하는 새로운 방법을 도입해서 큰 범위의 수를 표현한다. 과학적 표기법에서는 10진 소수점 왼쪽이 한 자리뿐인 소수에 10을 몇 번 거듭제곱한 값을 곱하는 방식으로 소수를 표현한다. 예를 들어 과학적 표기법에서는 0.0012 대신 $1.2 \times10^{-3}$이라고 쓴다. 2진법으로 표기할 때는 10이 아닌 2를 밑으로 한다는 점만 다를 뿐이다. 따라서 가수 부분은 2진 소수, 지수 부분은 2의 거듭제곱 횟수를 표현한다.
여기서 지수의 밑인 2라는 숫자를 비트로 표현할 필요는 없다. 부동소수점 수의 정의상 밑 2는 항상 정해져 있다. 부동소수점 표현법은 지수와 가수를 분리함으로써 수를 표현할 때 필요한 (소수점 왼쪽에 연속으로 나타나거나 소수점 오른쪽에 연속으로 나타나는) 0을 모두 저장하지 않고도 큰 수나 작은 수를 표현할 수 있다.
예를 들면 2비트 가수와 2비트 지수를 사용하는 4비트 부동소수점 수 표현은 다음과 같다
- 0 0 . 0 0 → $0 \times 2^0 = 0$
- 0 1 . 0 1 → $\frac12 \times 2^1 = 1.0$
- 1 1 . 1 1 → $1 \frac12 \times 2^3 = 12.0$
이 예제는 단지 4비트만 사용하지만 부동소수점 표현법의 비효율성을 여실히 보여준다. 첫째, 비트 조합 중에 낭비되는 부분이 많다. 예를 들어 0을 표현하는 방법은 4가지나 있다. 둘째, 비트 패턴이 가능한 모든 수를 다 표현하지는 못한다. 지수가 커질수록 가수의 한 패턴과 다른 패턴 사이이의 값 차이가 커진다. 이로 인해 0.5와 0.5를 더하면 1.0을 얻을 수 있지만 6.5를 표현하는 비트 패턴이 없기 때문에 0.5와 6.0을 더할 수는 없다는 부작용이 생긴다.
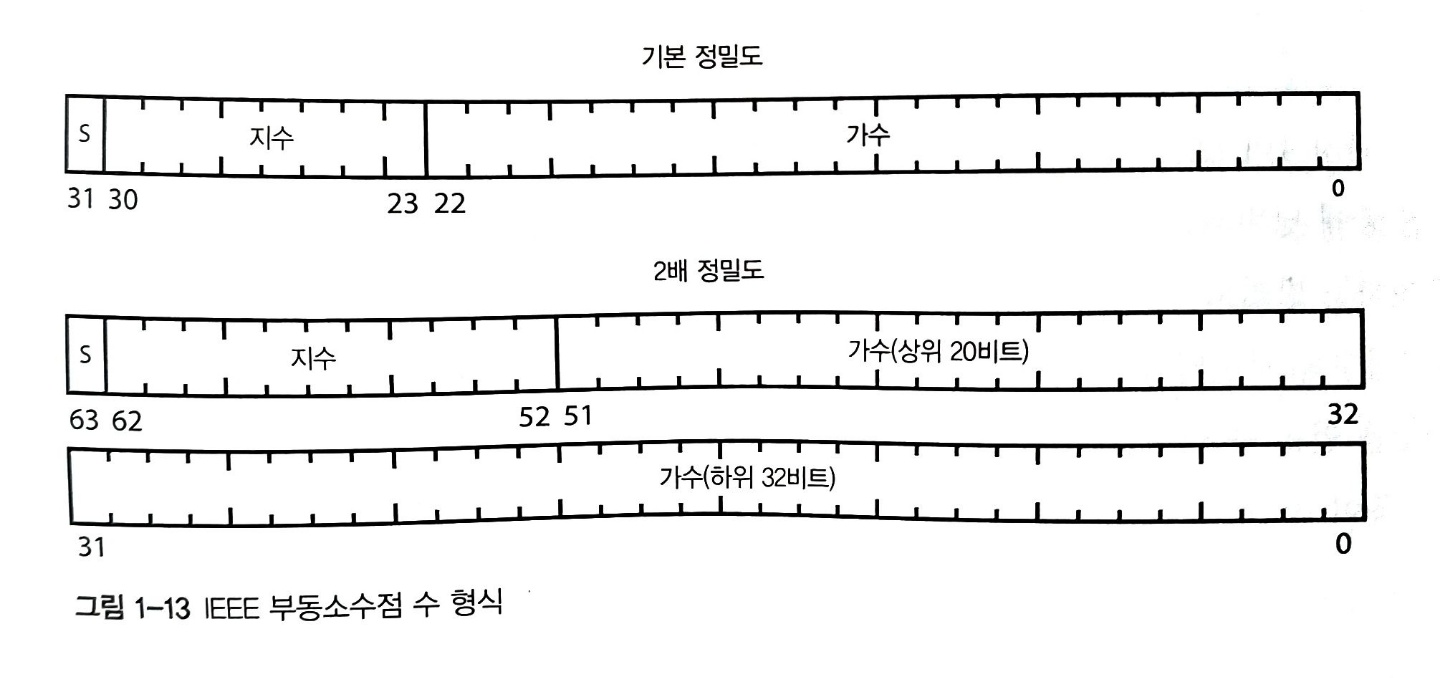
IEEE 부동소수점 수 표준
이상하지만 부동소수점 수 시스템은 컴퓨터에서 계산을 수행할 때 실수를 표현하는 표준 방법이다. 위의 예제보다 더 많은 비트를 사용하며, 가수와 지수에 대해 각각 부호 비트를 사용한다. 똑같은 비트를 사용하더라도 정밀도(precision)를 가능한 한 높이고 싶다.
- 한 가지 트릭은 정규화(normalization)다. 정규화는 가수를 조정해서 맨 앞에 0이 없게 만드는 것이다. 이런 식으로 가수를 조정하려면 지수도 조정해야 한다.
- 두 번째 트릭은 디지털 이큅먼트(DEC, Digital Equipment Corp.)사에서 고안한 것으로, 가수의 맨 왼쪽 비트가 1이라는 사실을 알고 있으므로 이를 생략하는 것이다. 이로 인해 가수에 1비트를 더 사용할 수 있다.
IEEE 754의 세부 사항을 모두 알 필요는 없지만, 두 가지 부동소수점 수가 자주 쓰인다는 사실을 알아둬야 한다. 한 가지는 기본 정밀도(single precision) 부동소수점 수이고, 다른 한 가지는 2배 정밀도(double precision) 부동 소수점 수다. 기본 정밀도 수는 32비트를 사용하며 7비트 정밀도로 대략 $\pm 10^{\pm38}$ 정도의 범위를 표현할 수 있다. 2배 정밀도 수는 64비트를 사용하기 때문에 더 넓은 범위를 표현할 수 있으며, 대략 $\pm 10^{\pm308}$ 범위의 수를 15비트 정밀도로 표현할 수 있다. 아래 그림은 두 부동소수점 수의 비트 형식을 보여준다.
텍스트 표현
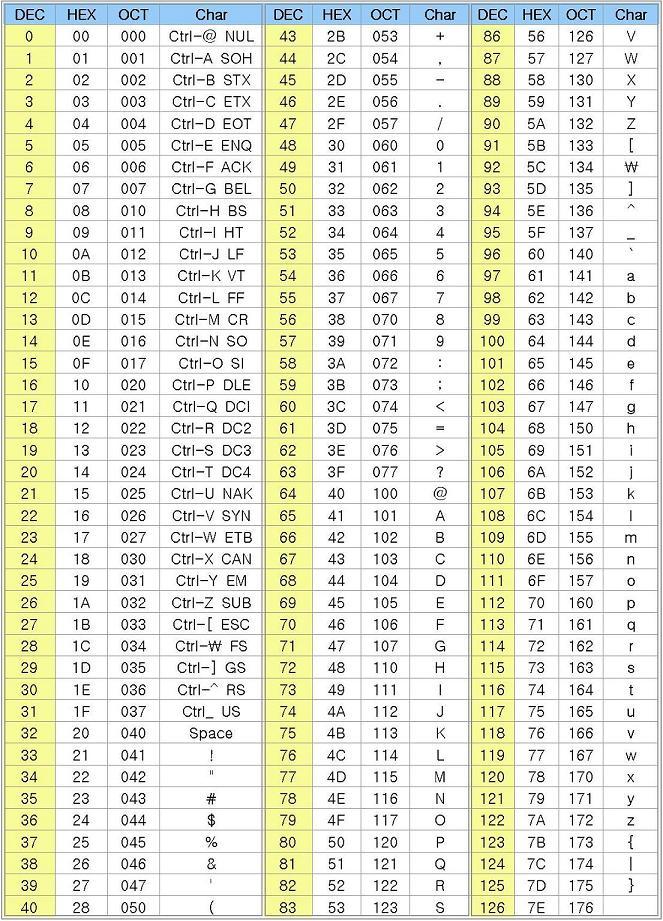
아스키 코드
수와 마찬가지로 텍스트를 표현하는 방법의 경우에 몇 가지 아이디어가 서로 경쟁했다. 1963년부터 승자는 아스키(ASCII, American Standard Code fro Information Interchange)였다. 아스키는 키보드에 있는 모든 기호에 대해 7비트 수를 할당했다. 예를 들어 65는 대문자 A를, 66은 대문자 B를 표현한다.
아스키 코드 표에서 몇 가지 재미있는 코드가 있다. 이런 코드들은 글자를 출력하는 데 쓰이지 않고 장치를 제어하기 위해 쓰이기 때문에 제어 문자(control character)라고 불린다.
다른 표준의 진화
아스키는 영어를 표현하는 데 필요한 모든 문자를 포함하고 있어서 상당 기간 표준 역할을 했다. 하지만 컴퓨터가 널리 쓰이게 됨에 따라 그 밖의 언어를 지원해야 할 필요가 점차 늘어났다. 국제 표준화 기구는 ISO-646 등을 통해 아스키를 확장해 유럽 언어에 필요한 액센트 기호나 그 밖의 발음 구별 기호를 추가했다. 또한 일본 문화를 표현하기 위해 JISX 0201을 만들었다. 그 외에도 중국어, 아랍어, 한국어 표준도 생겼다.
이렇게 각기 다른 표준이 존재한 이유는 비트가 지금보다 더 비싼 시절에 표준이 만들어졌기 때문이다. 그래서 문자를 7비트나 8비트에 욱여넣었다. 비트 가격이 떨어짐에 따라 유니코드(Unicode)라는 새로운 표준이 만들어졌고, 문자에 16비트 코드를 부여했다. 그 후 유니코드는 21비트까지 확장되었다.
유니코드 변환 형식 8비트
유니코드는 문자 코드에 따라 각기 다른 인코딩을 사용해 8비트로 저장된 아스키 코드 문자를 16비트로 표현하여 문제를 해결한다. 인코딩(encoding)은 다른 비트 패턴을 표현하기 위해 사용하는 비트 패턴을 뜻한다. 우리는 비트 같은 추상화를 사용해 숫자를 표현하고, 숫자를 사용해 문자를 표현하며, 다시 다른 숫자를 사용해 이런(문자를 표현하는) 숫자를 표현한다.
UTF-8(유니코드 변환 형식 8비트)라는 인코딩 방법이 하위 호환성과 효율성 때문에 가장 널리 쓰이고 있다. UTF-8은 모든 아스키 문자를 8비트로 표현하기 때문에 아스키 데이터를 인코딩 할 때는 추가 공간이 필요하지 않다. 그리고 UTF-8은 아스키가 아닌 문자의 경우 아스키를 받아서 처리하는 프로그램이 꺼지지 않는 방법으로 문자를 인코딩한다.
UTF-8은 문자를 8비트 덩어리(옥텟)의 시퀀스로 인코딩한다. UTF-8에서 교묘한 부분은 첫 번째 덩어리(8비트)의 MSB 쪽에 있는 비트들이 8비트 덩어리(옥텟) 시퀀스의 길이를 표현하고, (MSB 쪽의 비트 패턴이 겹치지 않아서) 덩어리의 맨 앞을 식별하기 쉽다는데 있다. 프로그램이 문자 경계를 찾아야 하는 경우 이런 특성이 아주 유용하다. 모든 아스키 문자는 7비트에 들어가기 때문에 덩어리를 하나만 사용해 표현할 수 있다. 영어의 경우 비 아스키 기호를 사용하는 언어보다 더 적은 용량으로 문자를 인코딩할 수 있기 때문에 영어 사용자에게는 이런 특성이 아주 편리하다. 아래 그림은 UTF-8이 유니코드 문자를 어떻게 인코딩 하는지 보여준다.
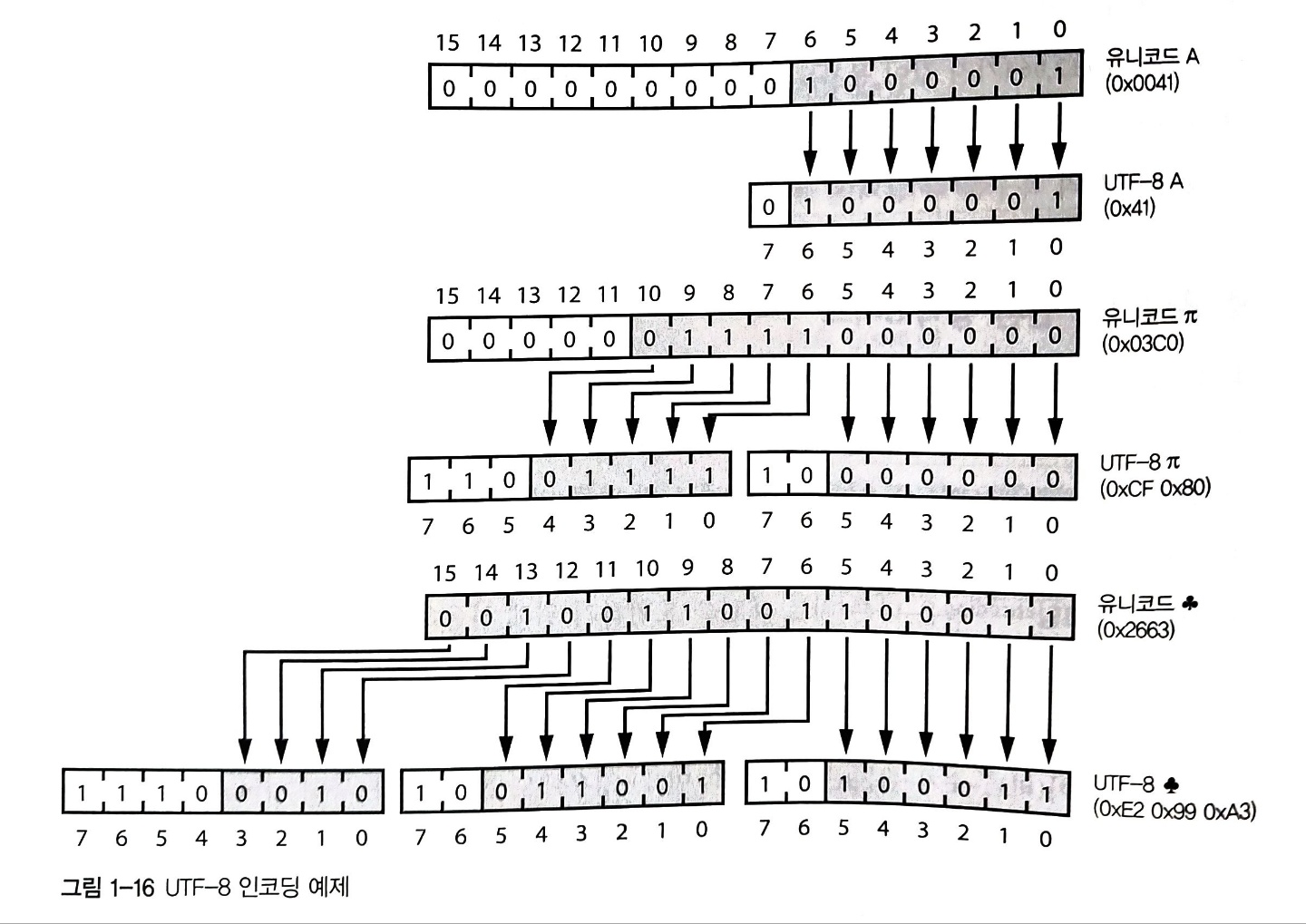
문자를 사용한 수 표현
UTF-8은 문자(예: A)를 표현하는 비트들(2진수 00000000010000000)로부터 나온 숫자들(0x0041)을 표현하는 숫자들(UTF-8로 인코딩한 값)을 표현하기 위해 숫자(실제 UTF-8로 인코딩한 0x41)들을 사용한다. 이제는 문자를 사용해 수를 표현할 수 있다.
베이스64 인코딩
베이스64 인코딩은 3바이트 데이터를 4문자로 표현한다. 3바이트 데이터의 24비트를 네 가지 6비트 덩어리로 나누고, 각 덩어리의 6비트값에 출력 가능한 문자를 할당해 표현한다. 이 때 아래 표와 같은 변환을 사용한다.
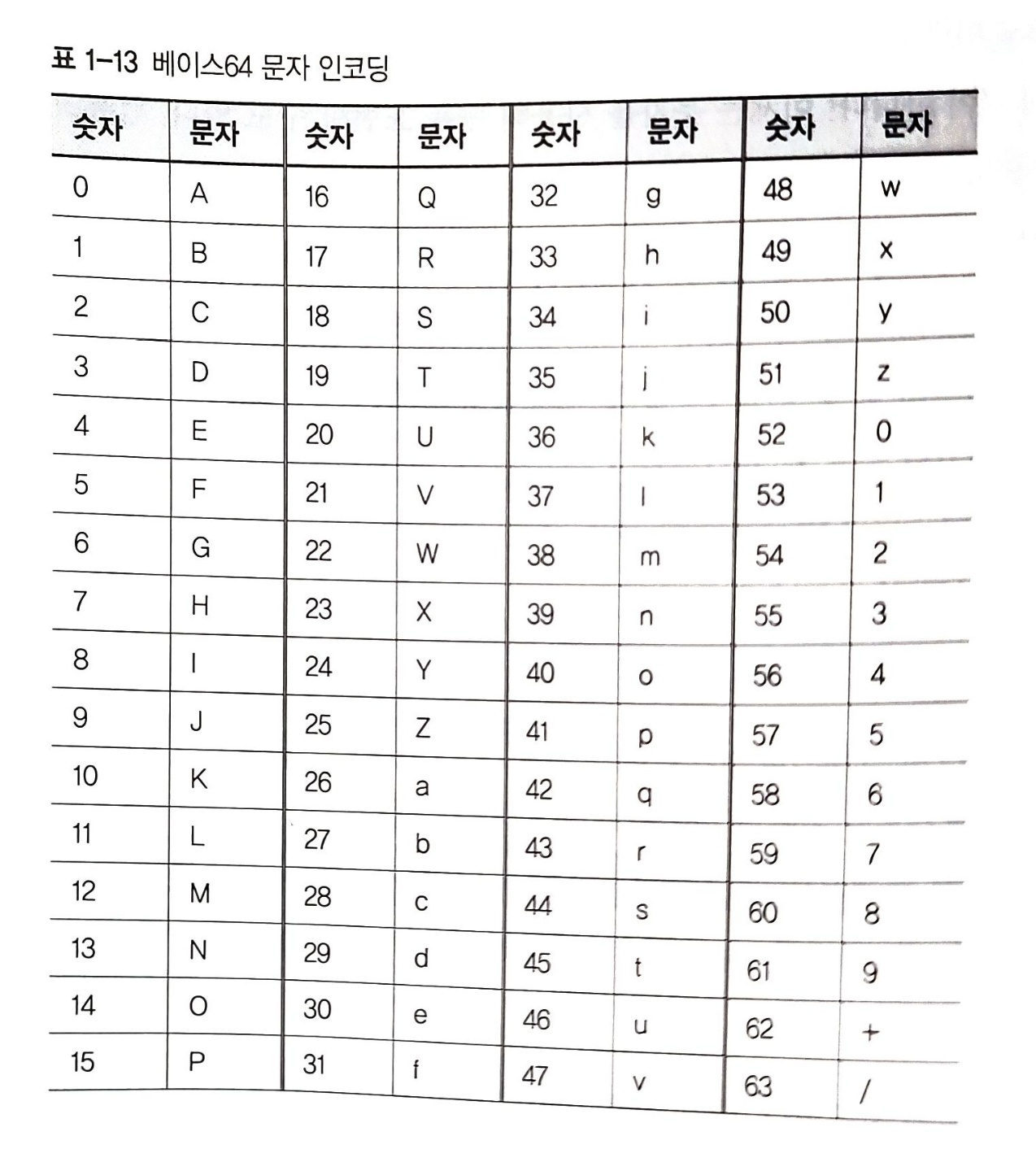
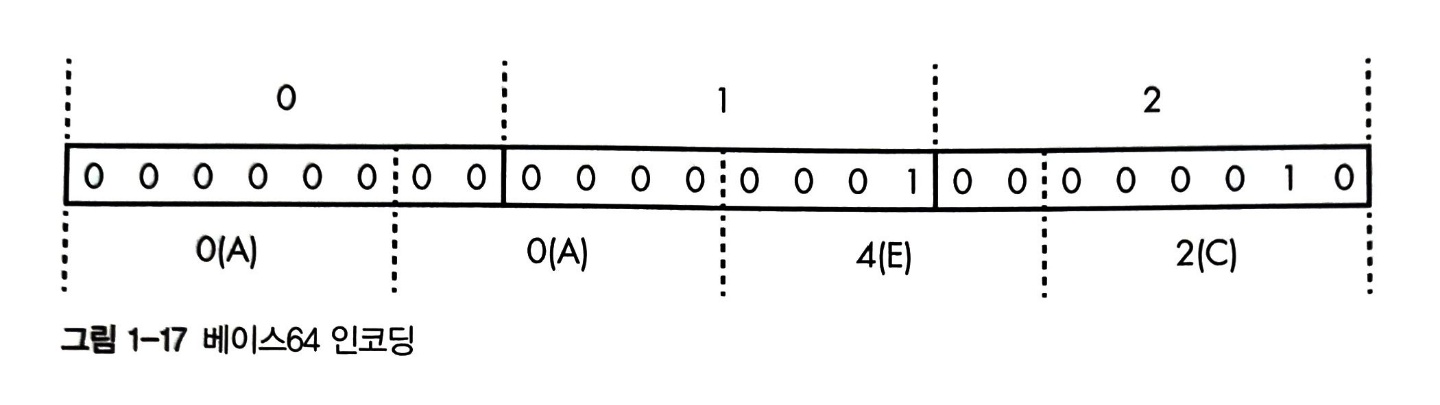
0,1,2라는 세 바이트를 인코딩하면 AAEC다. 아래 그림은 이 변환 과정을 보여준다.
이 인코딩은 모든 3바이트 조합을 4바이트 조합으로 변환할 수 있다. 하지만 원본 데이터 길이가 3바이트의 배수라는 보장은 없다. 패딩(padding) 문자를 도입해 이런 문제를 해결한다. 원본 데이터가 2바이트 남으면 끝에 =를 붙이고, 1바이트 남으면 끝에 ==를 붙인다.
참고자료 : <한 권으로 읽는 컴퓨터 구조와 프로그래밍> 조너선 스타인하트 저