[동시성 프로그래밍] Ch1. 동시성과 병렬성

1.1 프로세스
존재론적으로 설명하는 물질에는 사물과 프로세스가 있다.
사물은 공간상에서 넓이를 갖지만 시간적인 넓이는 갖지 않는 것이며, 프로세스는 공간과 시간의 넓이를 모두 갖는 것이다. 즉, 사물은 특정한 시점에 전체가 존재하지만 프로세스는 특정한 시점에 일부만 존재한다.
다만, 이 책에서는 어떤 계산을 수행하는 추상적인 계산 실행 주체라는 계산과 관련된 프로세스만 가리킨다. 이 책에서는 프로세스를 다음과 같이 정의한다.
프로세스란 계산을 실행하는 주체를 가리키며 크게 다음 네 가지 상태를 변경하면서 계산을 진행한다.
- 실행 전 상태 : 계산을 실행하기 전의 상태. 실행 상태로 전이할 수 있다.
- 실행 상태 : 계산을 실행하고 있는 상태. 대기 상태 또는 계산 종료 상태로 전이할 수 있다.
- 대기 상태 : 계산을 일시적으로 정지한 상태. 실행 상태로 전이할 수 있다.
- 종료 상태 : 계산을 종료한 상태
아래 그림은 프로세스의 상태 전이를 보여준다.
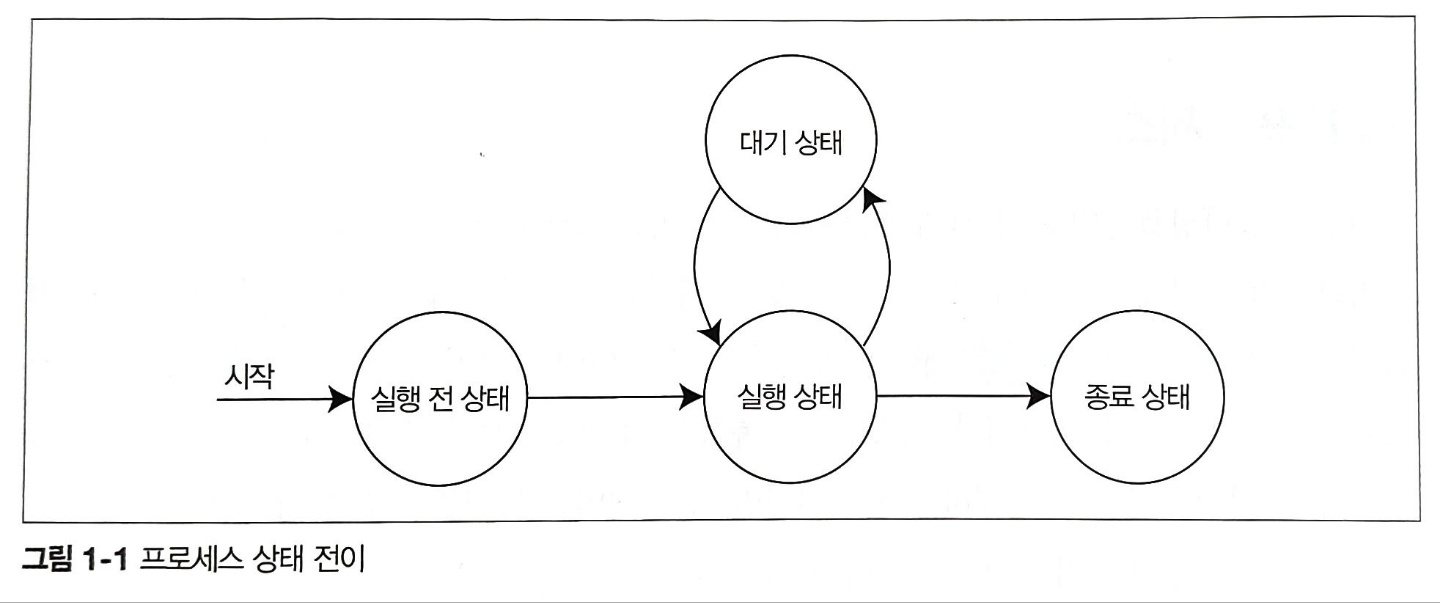
그림에서 알 수 있듯이 프로세스의 상태는 실행 전 상태에서 시작해 실행 상태, 대기 상태를 거쳐 종료 상태로 전이한다. 즉, 프로세스는 항상 실행 상태인 것이 아니라 실행 전 상태에서 종료 상태로 전이하는 도중에 대기 상태가 될 수도 있다. 대기 상태로 전이하는 이유는 다음 세 가지다.
- 데이터가 도착하기를 기다린다.
- 계산 리소스의 확보를 기다린다.
- 자발적으로 대기 상태로 진입한다. (ex. timer)
1.2 동시성
동시성(concurrency)은 2개 이상의 프로세스가 동시에 계산을 진행하는 상태를 나타낸다. 다음 그림은 임의의 2개 프로세스의 상태 전이를 시간 축에 따라 나타낸 것이다.
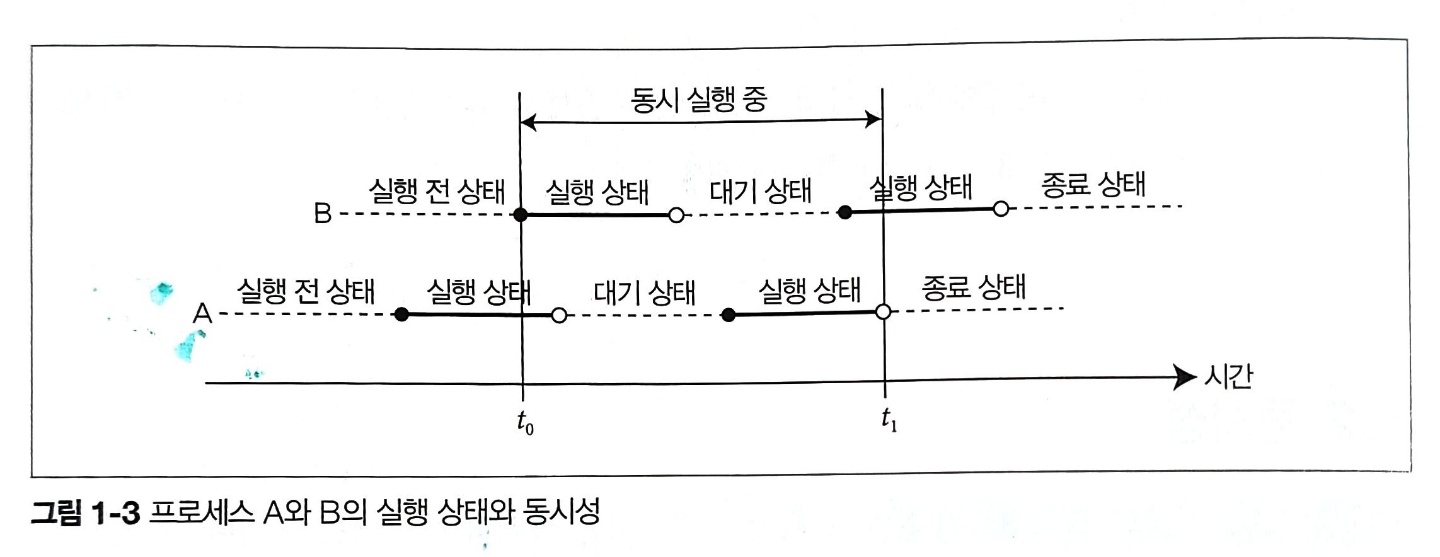
위 예에서 프로세스 A가 프로세스 B보다 먼저 실행 전 상태에서 실행 상태로 전이하며, 먼저 종료 상태로 전이한다. 따라서 앞의 정의에 따라 A, B 두 프로세스가 계산 중 상태인 시간 t | $t_0$ ≤ t < $t_1$일 때 프로세스 A와 프로세스 B는 동시에 실행 중이라 할 수 있다.
OS 프로세스와 쓰레드에 대해서 간단히 살펴보자. 일반적으로 OS 프로세스는 커널에서 본 프로세스를 의미하며, 스레드는 OS 프로세스 안에 포함된 프로세스로 분류된다. 많은 경우 어플리케이션을 기동하면 하나(또는 소수)의 OS 프로세스가 생성되고, 그 OS 프로세스 안에서 여러 스레드를 만든다.
다음 그림은 OS 프로세스와 스레드의 특징을 간단히 나타낸 것이다.

위 그림과 같이 OS 프로세스에서는 OS가 각 프로세스에 독립된 가상 메모리 공간을 할당하고, 각 스레드는 소속된 OS 프로세스의 가상 메모리 공간과 시스템 자원을 공유한다.
실제 리눅스의 경우 스레드는 경량의 OS 프로세스로 구현되어 있으며 스케줄링 할 때도 일반적인 프로세스와 마찬가지로 취급되기 때문에 구현 면에서는 거의 차이가 없다고 할 수 있다. 한편 nmap 등을 이용하면 프로세스 사이에서 메모리 공간을 공유할 수 있으므로 프로세스 사이의 메모리가 완전히 다른 공간이라고 말할 수는 없다. 어쨌든 OS 프로세스나 스레드 모두 동시성을 구현하기 위한 메커니즘 이라고 생각하면 된다.
1.3 병렬성
병렬성(parallelism)은 같은 시각에서 여러 프로세스가 동시에 계산을 실행하는 상태를 의미한다. 아래 그림은 프로세스 A와 B의 상태 전이를 시간 축 위에 나타낸 것으로 프로세스 A와 B가 병렬 실행되는 시간을 표시한 것이다. 이 예에서는 시각 t < $t_0$ ≤ t < $t_1$, $t_2$ ≤ t < $t_3$ 일 때 프로세스 A와 프로세스 B가 모두 실행되고 있으므로 시각 t에서 프로세스 A와 프로세스 B는 병렬 실행 중이라고 할 수 있다.
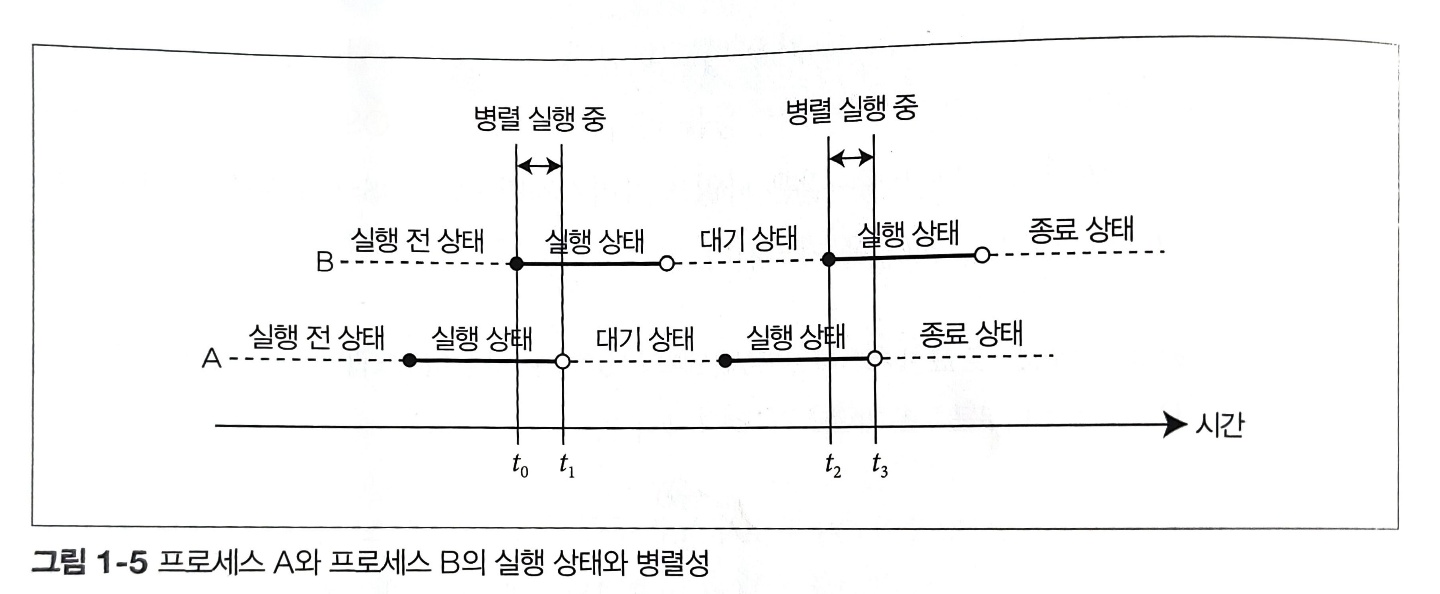
이는 프로세스 관점에서 병렬성을 정의한 것이다. 컴퓨터 아키텍처, 즉 하드웨어에서 보면 병렬성은 태스크 병렬성, 데이터 병렬성, 인스트럭션 레벨 병렬성 3종류로 나뉜다.
1.3.1 태스크 병렬성
태스크 병렬성은 여러 태스크(프로세스)가 동시에 실행되는 것을 의미한다. OS는 계산 처리를 OS 프로세스 또는 스레드라 불리는 프로세스로 추상화하고 있으며, 태스크 병렬 처리에서는 이 OS 프로세스 또는 스레드를 여러 CPU를 이용해 동시에 작동시킨다.
1.3.2 데이터 병렬성
데이터 병렬성은 데이터를 여러 개로 나누어서 병렬로 처리하는 방법이다. 만약 연산기가 4대라면 각 계산을 4대의 연산기에서 따로 계산하므로 보다 빠르게 실행할 수 있다. 이를 데이터 병렬 처리에서 벡터 연산이라고 부른다.
응답 속도와 처리량
계산 속도에 관해 정리하고 넘어가자. 계산 속도는 응답 속도와 처리량(throughput)이라는 두 가지 척도로 생각해 볼 수 있다. 응답 속도는 계산을 시작해서 마칠 때까지의 시간을 나타낸다. 응답 속도를 나타내기 위해 소비 CPU 클록(clock)수나 수비 CPU 인스트럭션 수 등이 척도로 이용되는데, 이는 모두 시간으로 바꿀 수 있다. 처리량이란 단위 시간당 실행 가능한 계산량을 나타내며 단위로는 MIPS(Million Instructions Per Second, 1초당 몇백만 개의 인스트럭션을 실행할 수 있는지), FLOPS(FLoating point number Operations Per Second, 1초당 몇 번의 부동소수점 연산을 실행할 수 있는지) 등을 이용한다.
암달의 법칙
병렬화를 통한 응답 속도 향상 정도는 병렬화 가능한 처리 부분과 병렬화 불가능한 처리 부분의 비율 그리고 병렬화를 위한 오버헤드에 따라 결정된다. 다음 그림은 순차 처리를 병렬화할 때의 모습을 나타낸 것이다. 그림에서 실선으로 그려진 사각형은 병렬화 가능한 처리, 점선으로 그려진 사각형은 병렬화 불가능한 처리를 나타내며 실선 부분의 처리를 4병렬로 병렬화했다.
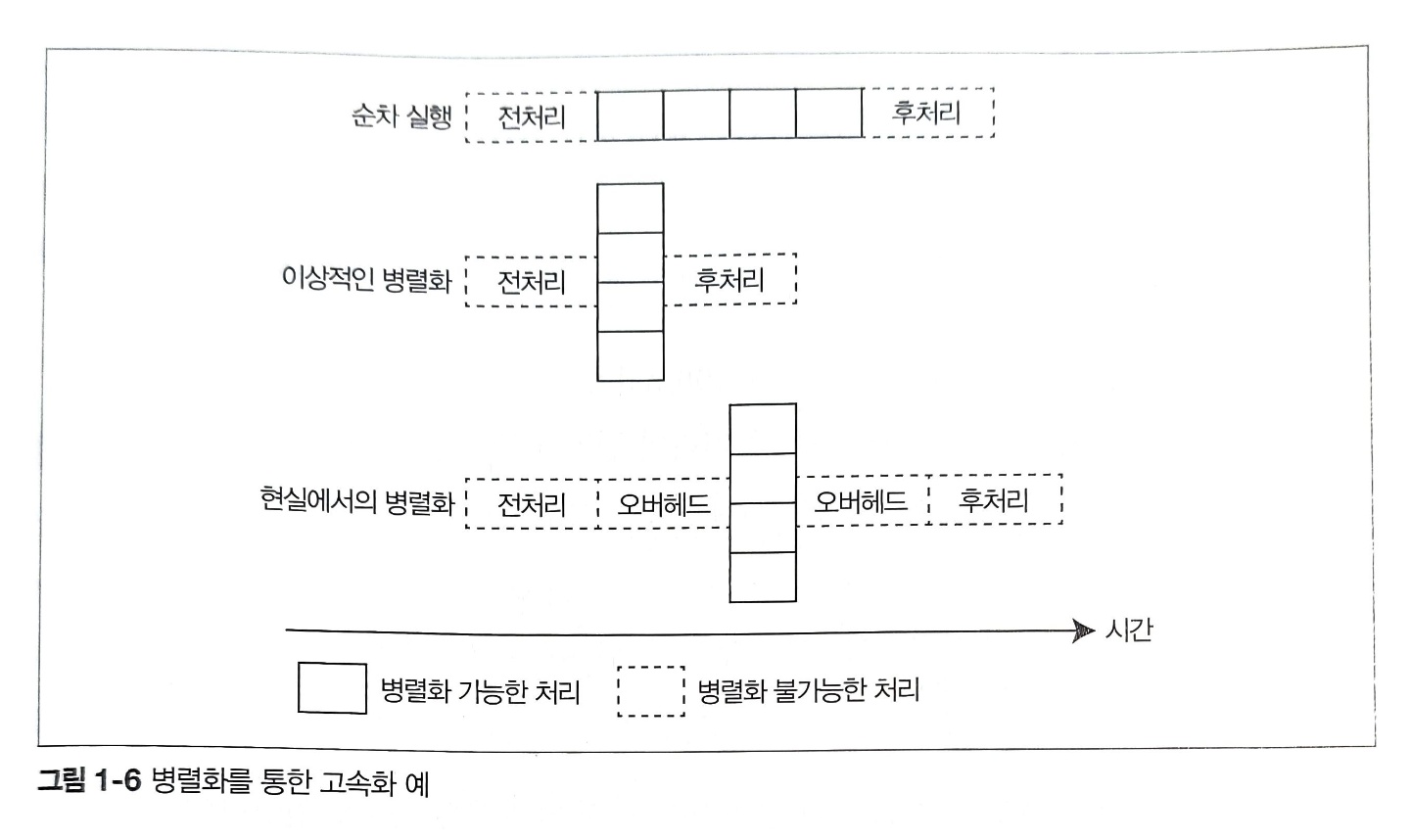
두 번째 그림을 보면 4병렬로 병렬화하면 순차 실행할 때보다 응답 속도가 향상되는 것을 알 수 있다. 하지만 현실에서는 스레드 생성이나 동기 처리 등 병렬화에 수반되는 오버헤드가 원인이 되어 세 번째 그림과 같이 순차 실행할 때보다 속도가 더 느려지기도 한다.
암달의 법칙(Amdhal’s Law)은 일부 처리의 병렬화가 전체적으로 고속화에 어느 정도 영향을 미치는지 예측하는 법칙이다. 암달의 법칙에 따르면 병렬화에 의한 응답 속도 향상률은 다음과 같다.
$$
1 \over (1 - P) + {P \over N}
$$
여기서 P는 전체 프로그램 중에서 병렬화 가능한 처리가 차지하는 비율, N은 병렬화 수다. 이 식은 병렬화에 수반되는 오버헤드가 없는 이상적인 상태에서 성능 향상률을 나타낸다.
1.3.3. 인스트럭션 레벨 병렬성
인스트럭션 레벨 병렬성은 이름 그대로 인스트럭션, 다시 말해 CPU의 명령어 레벨에서 병렬화를 수행하는 방법이다. 대단히 높은 수준의 최적화를 할 때는 프로그래머가 인스트럭션 레벨 병렬성까지 고려해야 한다.
인스트럭션 레벨 병렬성까지 고려해서 프로그래밍을 하는 예로는 루프 전개를 수행할 때나 데이터 프리패치를 수행하는 경우다. 루프는 전형적으로 조건문과 실제 실행을 수행하는 두 개의 구문으로 구성되며 조건문과 실제 실행문을 짧은 빈도로 반복하면 조건문이 원인이 되어 인스트럭션 레벨 병렬성이 낮아지기도 한다.
데이터 프리패치는 나중에 메모리에 있는 데이터를 이용해 계산을 수행할 것을 미리 알고 있을 경우 사전에 데이터를 메모리에 읽어두는 방법이다. 메모리에 미리 읽어두는 이유는 메모리 읽기 명령은 덧셈이나 뺄셈 같은 명령에 비해 응답 속도가 느린 명령이기 때문이다. CPU에 나열된 인스트럭션 레벨 병렬화 기능에 의해 메모리를 읽어 들이는 중에도 다른 덧셈이나 뺄셈 같은 연산 명령을 실행할 수 있기 때문에 메모리 읽기와 연산을 병렬로 실행 가능하다.