[GraphQL #1] GraphQL의 배경, 장단점 및 그래프 이론
해당 포스팅은 프로그래밍 인사이트에서 출판한 <웹 앱 API 개발을 위한 GraphQL> (이브 포셀로, 알렉스 뱅크스 저)을 바탕으로 작성한 글임을 먼저 밝힙니다.

GraphQL이란?
클라이언트의 종류가 다양해지고 복잡해지면서 서버로부터 데이터를 받아와서 빠르고 손실없이 클라이언트에 전송하는 기술은 끊임없이 발전해 왔고 현재도 진행 중에 있다. GraphQL은 이 과정에서 만들어진 쿼리 언어이다. GraphQL 쿼리는 실제로 필요한 데이터만 받도록 작성할 수 있다. 응답은 JSON 형태로 주어진다. 쿼리문을 중첩하여 실행하면 연관된 객체를 응답 데이터로 같이 받을 수도 있다.
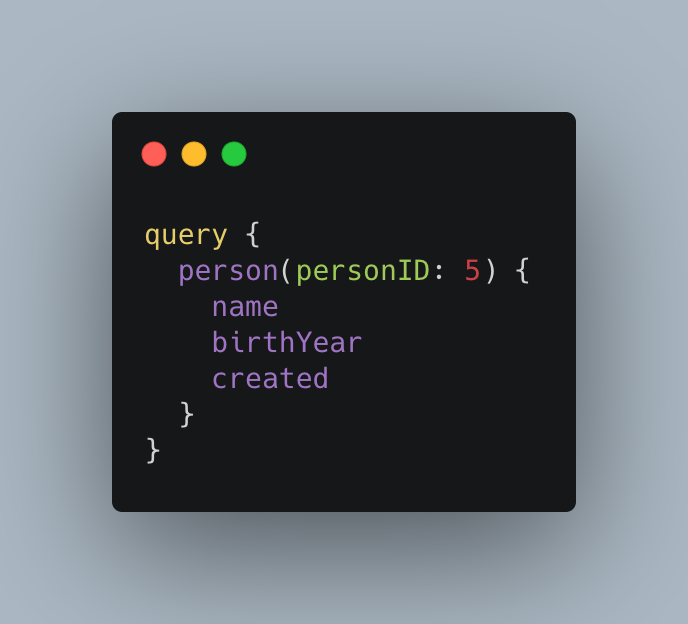
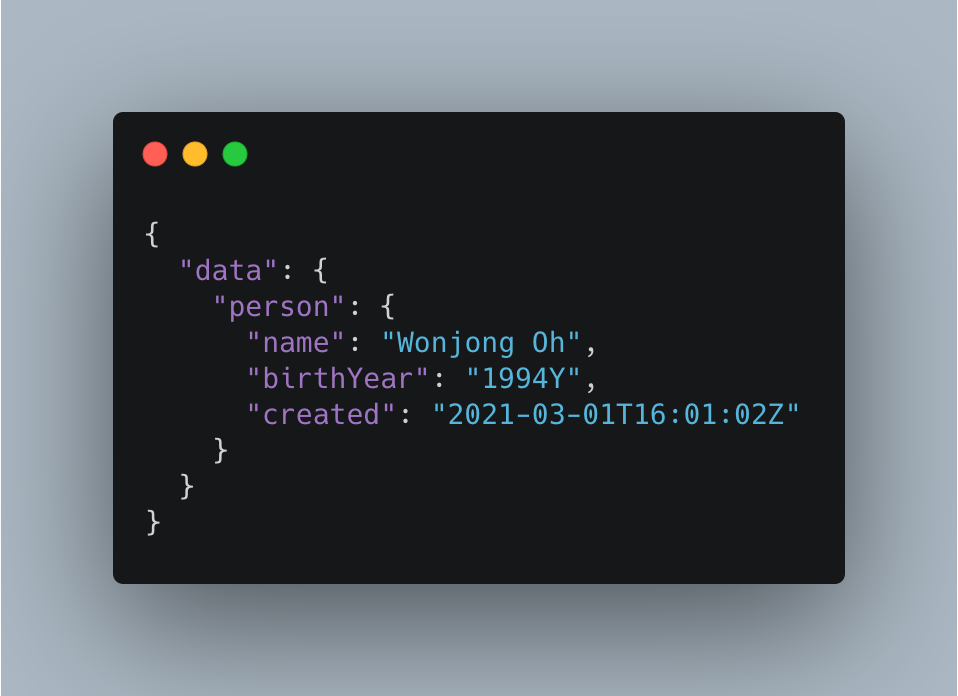
GraphQL 서버에서는 쿼리가 실행될 때마다 타입 시스템에 기초해 쿼리가 유효한지 검사한다. GraphQL 서비스를 만드려면 GraphQL 스키마에서 사용할 타입을 정의해야 한다. 이러한 타입 시스템은 앞으로 사용하게 될 API 데이터에 대한 청사진이라고 이해하면 된다.
GraphQL은 선언형(Declarative) 데이터 패칭(fetching) 언어이다. 개발자는 '무슨' 데이터가 필요한지에 대한 요구사항만 작성하면 되고 '어떻게' 가져올지는 신경쓰지 않아도 된다. GraphQL은 클라이언트와 서버간의 통신 명세이다.
GraphQL을 설계할 때는 다음 원칙을 지키면서 하는 것을 권장한다.
- 위계적: GraphQL 쿼리는 위계성을 띄고 있다. 필드 안에 다른 필드가 중첩될 수 있으며, 쿼리와 그에 대한 반환 데이터는 형태가 서로 같다.
- 제품 중심적: GraphQL은 클라이언트가 요구하는 데이터와 클라이언트가 지원하는 언어 및 런타임에 맞춰 동작한다.
- 엄격한 타입 제한: GraphQL 서버는 GraphQL 타입 시스템을 사용한다. 스키마의 데이터 포인트마다 특정 타입이 명시되며, 이를 기초로 유효성 검사를 받게 된다.
- 클라이언트 맞춤 쿼리: GraphQL 서버는 클라이언트 쪽에서 받아서 사용할 수 있는 데이터를 제공한다.
- 인트로스펙티브(introspective): GraphQL 언어를 사용하여 GraphQL 서버가 사용하는 타입 시스템에 대한 쿼리를 작성할 수 있다.
이전에 데이터 전송 역사에 대해서도 간단하게 짚고 넘어가자. GraphQL을 이해하는 데 도움이 될 수 있고, 비교분석하여 팀에서 적합한 방법을 결정할 때 도움이 될 수 있을 것이다.
- RPC(Remote Procedure Call) : 클라이언트에서 원격 컴퓨터로 요청 메시지를 보내 무언가를 하게 만든다. 원격 컴퓨터는 클라이언트로 응답 메시지를 보낸다.
- SOAP(Simple Object Access Protocol): XML을 사용해 메시지를 인코딩하고 HTTP를 사용해 전송한다. SOAP에서는 타입 시스템도 사용하고 리소스 중심의 데이터 호출 개념도 도입했다. 구현하기가 조금 복잡하다.
- REST: 아마 대부분에게 제일 익숙한 API 패러다임일 것이다. 사용자가 GET, PUT, POST, DELETE와 같은 행동을 수행하여 웹 리소스를 가지고 작업을 진행하는 리소스 중심 아키텍처이다. 리소스 네트워크는 가상 상태 머신(Virtual State Machine)이며 행동(GET, POST 등)은 머신 내의 상태를 바꾼다. REST를 사용하면 데이터 모델의 엔드포인트를 다양하게 만들 수 있다. 초반의 REST는 XML 형식과 함께 사용이 되었고(ajax), 이후에는 JSON 형식으로 표준화가 이루어지게 되었다.
이렇게 장점이 많은 REST를 잘 쓰고 있었는데 왜 페이스북 개발팀에서는 GraphQL을 만들게 되었을까? 지금부터는 REST가 가진 단점 및 한계에 대해서 살펴보기로 하자.
- 오버페칭: REST를 사용하면 필요하지 않은 데이터를 너무 많이 받아오게 된다. 클라이언트에서 필요한 데이터는 극히 일부분이지만 REST에서는 데이터를 전부 받아와야 하기 때문이다. 당연히(?) 이로 인해 성능 저하 문제가 발생한다.
- 언더페칭: API가 수정이 될 때 데이터를 추가적으로 요청해야 할 때가 있는데 이럴 때 중복해서 요청을 보내야 하는 상황이 발생할 수 있다. GraphQL을 사용하면 쿼리를 중첩으로 정의하여 페치 한 번으로 모든 데이터를 요청할 수 있다.
- 엔드포인트 관리: 클라이언트에서 변경 사항이 생기면 엔드포인트를 새로 만들어야 하는데 이렇게 될 때 REST 방식은 엔드포인트가 몇 배로 빠르게 늘어나게 된다. 이는 개발 속도를 저하시키는 원인이 된다. GraphQL을 사용하게 되면 설계 상으로 엔드포인트가 하나로 끝나게 된다.
그래프 이론
GraphQL을 본격적으로 들어가기 전에 알아두면 좋을 것 같은 내용이라 그래프에 대한 개념을 간단하게 정리하고 넘어가려고 한다.
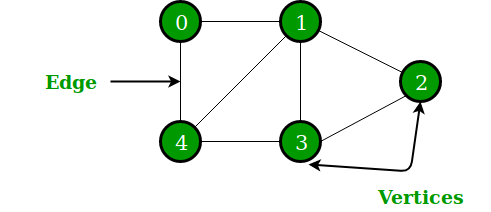
위와 같은 그림을 그래프 다이어그램(graph diagram)이라고 한다. 그래프는 데이터 포인트(data point) 객체와 이들 사이의 관계를 의미한다. 여기서 나타난 점들은 노드(node) 혹은 정점(vertex)이라고 하고 노드 사이의 연결선은 엣지(edge)라고 한다.
위의 그래프를 식으로 표현하면 다음과 같다.
vetices = { 0, 1, 2, 3, 4 }
edges = { {0, 1}, {0, 4}, {1, 2}, {1, 3}, {1, 4}, {2, 3}, {3, 4} }
이처럼 그래프에 방향이 없는 경우는 무방향 그래프(무향 그래프, undirected graph)라고 하며, 반면 방향이 있는 그래프는 방향 그래프(유향 그래프, directed graph)라고 한다.
GraphQL 프로젝트 안에서는 이러한 그래프에 대한 내용이 배경으로 깔려 있기 때문에 이를 이해하고 사용하면 더 잘 활용할 수 있다. 예를 들어 페이스북의 경우는 친구와 친구 사이에 무방향 그래프를 가지고 있지만 트위터나 인스타그램은 방향 그래프를 사용하고 있다.