IBM Developer Day 후기
지난 금요일 저는 IBM Developer Day를 다녀왔습니다.

IBM Developer Day는 전 세계 각국 IBM 지사에서 주최하는 개발자 컨퍼런스 입니다. IBM Korea에서 여는 연중 행사 중 가장 규모가 큰 것으로 알고 있어요. 저는 이번에 이 행사를 비교적 일찍 알게 되어서 빠르게 신청했는데, 무료 행사라 그런지 마감도 빠르게 되는 것 같더라구요. 혹시 내년에 참가를 하고 싶으시다면, 일찍 서두르시는 편이 좋을 것 같습니다 ㅎㅎ
발표 분야는 정말 다양했던 것 같아요. 웹, 딥러닝, 머신러닝, 블록체인, 클라우드 등등 주제로 발표가 이루어 졌고 IBM이 아닌 외부에서 오신 연사님들도 정말 많았어요. 저는 처음부터 순서대로 Track A, C, C, D, C, D 이렇게 들었습니다. 추후에 발표 자료나 영상은 공식 홈페이지에 업로드 된다고 하니 참고하시면 될 것 같아요!
장소는 르 메르디앙 호텔에서 했었고 그래서 그런지 정말 깔끔하고 쾌적했습니다. 다만, 대규모 무료 컨퍼런스다 보니 사람이 너무 많이 몰려서 조금 정신없었던 것 같기도 해요. 그리고 예전에 DEVIEW 2018 를 갔을 때는 여러가지 기념품을 많이 챙겨주었는데, 이번에는 그런게 별로 없어서 아쉬운 느낌? 그래도 발표 내용 자체는 정말정말 좋았던 것 같아요. 그러면 지금부터 제가 들었던 세션을 하나씩 적어 보도록 할께요.
헬로 딥러닝 - 직관적이고 명확하게 딥러닝을 이해하기
보이저엑스 남세동님
제가 이날 살짝 늦게 도착해서 앞부분 5분 정도는 놓쳤습니다..

세동님은 우리에게 익숙한 벽돌 깨기 게임으로 딥러닝을 설명해 주셨습니다. 지금까지는 벽돌 깨기 게임을 하는 프로그램을 짜려면 사람이 기존 도메인 지식(Domain Knowledge)을 가지고 코드를 짰는데, 딥러닝을 통해서는 그러한 기존의 방식으로 코드를 짠 것이 아니라고 하셨어요. 그래서 사람이 생각하지 못 한 방법으로 게임을 깨는 프로그램을 짤 수 있는 것이고 이는 알파고가 이세돌을 이길 수 있었던 이유라고 하셨습니다.
고양이 사진을 보여주면서 고양이인지 맞춰보라는 프로그램은 10년 전까지만 해도 없었습니다. 예를 들어 '다리가 4개이면 고양이다.'라는 명제가 있다면 이 명제를 가지고는 고양이 얼굴만 있는 사진을 판별할 수 없습니다. 그리고 다리가 4개인 동물이 고양이만 있는 것도 아니죠. 더 나아가 어떤 픽셀값을 가지고 다리라는 정보를 받아와야 하는지도 쉽지 않은 문제입니다.

이를 풀 수 있는 방법이 딥러닝입니다. 딥러닝은 Deep Neural Network를 활용한 머신러닝입니다. 이 신경망 구조를 따라서 곱하기 더하기를 하는 게 전부입니다. 벽돌깨기 인공지능도, 알파고도 결국은 이 곱하기 더하기를 어떻게 하는지에 따라 나온 모델이지요. 원래는 이 모델을 사람이 짰지만, 딥러닝을 통해서는 이 숫자들이 약 3000만~5000만개정도 나타나고, 이는 사람이 짠 프로그램이 아니어서 사람은 이해할 수가 없습니다.
예를 들어 바둑을 살펴보겠습니다. 바둑판은 19X19 그리드 형태로 이루어져 있고 바둑돌을 올려 놓을 수 있는자리는 총 400개가 됩니다. 각 자리에는 3가지의 숫자를 넣을 수 있죠. -1(검은돌), 0(비어있음), 1(흰돌) 이런 식으로 말이지요. 이 400개의 값들을 입력값으로 다 받아서 각각에 w(가중치, weight factor)를 곱한 뒤 더하고 계산을 하면 출력값으로 x,y좌표 두 개의 숫자가 반환이 되고 이 방법으로 알파고는 이세돌을 이겼습니다.

세동님은 회사에서 만든 데모 서비스도 소개했습니다. brain.js 인데, 사용자가 여러가지 배경 색상에 대해서 더 잘보이는 색상(b/w)을 선택하면 그에 맞게 랜덤 배경색에 대해 글자색을 추천해 주는 서비스입니다. 일반적인 알고리즘은 rgb값을 받아서 평균을 낸 뒤에 회색을 만들고 그 값이 흰색에 가까운 흰색, 검은색에 가까우면 검은색으로 결과를 냅니다. 하지만 brain.js는 약 20~30개의 데이터만을 받아도, 그 데이터들을 통해 마치 3차원(rgb) 블록에서 케잌 자르듯 잘라서 결과를 알려준다고 합니다.
이 외에도 보이저엑스의 여러 서비스를 소개해 주셨습니다. 모바일 스캐너의 경우 책의 굴곡진 부분이 있는 경우 글자를 인식하기가 어려운데 보이저엑스에서 이를 딥러닝을 사용하여 세계 최초로 풀었다고 하셨습니다. 또한 영상편집 서비스도 인터뷰를 녹화를 하면 옆에 자막이 자동으로 텍스트로 뜨고, 마치 워드처럼 영상편집을 할 수 있다고 합니다. 이로 인해 실제 사용자들은 기존의 방법에 비해 영상편집을 하는 데 시간이 정말 단축된다고 하더라구요. 마지막 데모는 폰트를 100자 정도만 학습을 시키면 자동으로 11000자 이상의 한글 폰트를 만들어주는 서비스 입니다. 이로 인해 더 다양한 한글 폰트를 사용할 수 있으며, 사람이 만들기 힘든 글자도 폰트 작업을 통해서 만들 수 있다고 해요.

세동님은 딥러닝이 신경망을 통해서 숫자에서 패턴을 찾는 것이라고 말씀해 주셨습니다. 마치 과거에 뉴턴이 F=ma라는 공식을 만들기 위해서 수많은 실험데이터를 분석한 것처럼 말이지요. 지금까지는 이러한 패턴을 사람이 찾았지만, 기술이 발전하고 복잡해지면서 이제는 사람이 만들지 못하는 영역이 생겨나기 시작했습니다. 예를 들면, 이세돌을 이기는 것이나 자율 주행 알고리즘을 만드는 것 등이 해당됩니다. 이러한 영역들을 기계가 코딩을 해서 해결할 수 있으며, 이것이 딥러닝이라고 하시는 부분에서 저는 발표가 굉장히 뜻깊었다고 생각을 합니다.
미우나 고우나 내새끼 : Reusable Custom Component 만들기 A to Z
Zepl 진유림님

유림님의 발표는 제가 관심있어 하는 웹 프론트엔드에 관한 주제였습니다. 컴포넌트 재사용에 대한 주제로 저도 많은 고민을 하고 있던 부분이기도 했구요. 이날 들었던 발표 중에서 가장 실무적으로 도움이 되었던 것 같아요. 유림님은 zepl이라는 스타트업에서 현재 웹 프론트엔드 엔지니어로 근무를 하고 계시고 zepl은 데이터 사이언스 버전 구글 독스라는 설명을 해 주셨어요.
웹 개발 기술이 점점 발전함에 따라서 이제는 사용자와의 상호작용을 하는 영역이 늘어나고 있고 이러한 상태를 관리하는 부분이 점점 중요해 지고 있습니다. 예를 들어 논문 공유 서비스를 생각해 보았을 때, 과거에는 그냥 단순하게 논문의 내용만 제공하는데에서 그쳤다면, 이제는 논문에 사용자가 좋아요를 누를 수 있고, 그 좋아요를 누른 순서대로 사용자에게 보여줄 수 있는 이러한 사용자 인터렉션이 생겨났습니다. 여기에서 프론트엔드 전용 데이터베이스가 필요한데 이를 우리는 상태(state)라고 부르게 됩니다.

유림님은 6 단계로 재사용이 가능한 커스텀 컴포넌트를 만드는 과정을 본인의 경험에 비추어서 설명해 주셨습니다.
- 디자인 -> (상태&액션&UI)
- 다른 라이브러리 조사
- 사용자 입장에서 MVP 컴포넌트 설계
- 배포 & 테스트 (이 부분 정확하게 기억이 잘 안남..)
- 세부 기능 붙이기
- 문서화

디자인을 받아서 상태와 액션을 정의하는 것부터, 기존의 라이브러리를 참고해서 요구사항을 분석해 보고, 사용자 관점에서 컴포넌트 설계, 세부기능을 목적에 맞게 stateful/stateless로 구현하고, 마지막으로 잘 정리해서 다른 팀원들도 보고 문제없이 쓸 수 있게 문서화까지... 프론트 엔지니어가 생각보다 더 꼼꼼하고 섬세하게 일을 해야 하는 직업이라는 걸 깨닫는 순간이었습니다. 많은 자극을 받았던 강의였고 저에게는 그래서 되게 유익했던 것 같습니다.
DevOps 도입이 왜 한국에서 실패하는가?
IBM 공진기님

진기님의 발표는 예전에 IBM IoT 밋업 이후로 두 번째 였습니다. 두 번의 발표를 들으면서 '정말 다양한 분야의 넓은 지식을 갖고 계신 분'이라는 생각이 들었던 것 같습니다. 이번 강연 주제는 DevOps, 더 나아가 한국 개발 문화에서 고쳐할 부분들에 대해서 다루었습니다.
※ DevOps란?
Development와 Operations의 합성어로 시스템 개발과 운영을 병행 및 협업하는 방식. 개발 부문, 운영 부문, 품질 관리 부서 사이의 통합, 커뮤니케이션, 협업을 위한 일련의 방법 및 시스템으로 적기에 소프트웨어 제품이나 서비스 출시를 목표로 하는 조직의 속성상 개발과 운영은 상호 의존을 해야 한다는 의미를 갖고 있다. 출처 : 네이버 지식백과
진기님은 MSA(Micro Service Architecture), Cloud, DevOps 삼 박자가 맞춰져야 Agile 방법론을 실천할 수 있다고 말씀하셨습니다. 이 세 가지 요소 중에 하나가 데브옵스이고 한국 개발 문화에서 애자일과 데브옵스를 방해하는 블로커들이 무엇인지, 그리고 이에 대해 회사/팀/개인 차원에서 어떠한 노력을 할 수 있는지에 대해서 알아보았습니다.
사용하는 툴 관련하여 먼저 이야기를 해주셨습니다. SCM(Source Code Management), Editor, Issue&Communication 부분으로 나누어서 설명을 하셨는데, 기존에 회사에서 오랫동안 쓰고 있는 툴에 익숙해진 나머지 새로운 변화를 받아들이는 것에 유연하지 못한 태도를 가진 회사가 많다는 점을 지적하셨습니다. 아직도 git을 안 쓰고 subversion을 고집하거나, IntelliJ나 VS Code 대신 Eclipse를 고집하는 등 말이지요. 그러한 툴들이 비용을 지불해야 되는 경우도 있지만, 비싼 개발자 연봉에 비해서 이러한 툴을 위해 투자하는 것은 정말 작은 부분이며, 이로 인해 생산성이 향상된다면 그것이 더 큰 가치라는 이야기를 해 주셨습니다. 협업 툴도 회사 메신저보다는 이러한 업무에 특화되어 나온 Jira, Confluence, Slack 등을 적극적으로 도입할 것을 권장하였습니다. 특히 Jira의 경우 저도 써본 적은 없지만, 코드와 연결시켜서 프로젝트 관리가 가능하기 때문에 이슈 검색 및 담당자 태그 등 애자일 방법론을 도입한다면 훨씬 더 높은 생산성을 기대할 수 있을 것이라고 말씀해 주셨습니다.
조직이 소스나 좋은 사례를 서로 공개하지 않는 점도 지적했습니다. 팀별, 부서별 경쟁이 심해서 버그가 나타나도 일부러 공개하지 않고, 좋은 사례를 꽁꽁 숨겨서 자신이 속한 팀에 유리하게 만들려는 경쟁 문화는 지양해야 한다고 하셨습니다. 진기님은 그래서 개발 공유 문화를 장려하고, 사내 소스코드를 오픈하며, API를 공개하고 타팀 좋은 사례를 활용하는 등 조금 더 서로 업무에 대해서 공유할 수 있는 문화를 만들어야 함을 주문했습니다.
한국에서 회사별로 망 분리가 되어 있고, 개발 서버는 혼잡하게 섞여 있으며, 개발용 랩탑도 맥을 지원해 주지 않는 부분도 개선해야 할 점으로 보았습니다. 또한 한국의 개발 프로젝트 구조가 갑(발주사)-을(구축사, 운영사)-병(협력사)로 이루어져 있기 때문에 좋은 결과를 낼 수 없다는 점도 지적했습니다. 발표를 들으면서 한국 개발의 현 주소를 너무 적나라하게 보는 것 같아서 많이 답답했습니다. 그럼에도 불구하고 이러한 문제를 인식하고 해결할 수 있도록 노력하시는 분들이 있다는 점에서 희망을 보기도 했습니다.

마지막으로 진기님은 회사에서 흔들리지 않는 조직이 있고 best practice를 보여주어, 그 사람을 따라할 수 있게 자연스러운 변화를 이끌어 나가는 식으로 회사에서 긍정적인 문화가 퍼져야 함을 요청했습니다. 개인도 다른 회사에서 탐나는 인재가 될 수 있도록 스스로 성장할 수 있게 노력해야 하고 회사는 이런 좋은 인재를 잡기 위해서 신경을 써야 한다고 하였습니다. 스스로도 좋은 인재가 되기 위해서 많은 노력을 해야 함을 느끼게 되는 의미 있는 발표였습니다.
개발자 취업의 수문장 코딩테스트 통과하기
뷰티풀 프로그래밍 김경록님

잠깐의 Coffee break를 가지고 나서 네번째 강연을 들었습니다. 경록님은 8년차 백엔드 개발자이시고, 여러 권의 개발 서적도 집필하신 경험이 있다고 하셨습니다. 이번에는 취준생들이 가장 관심있을 만한 코딩테스트에 대한 주제였고, 저 역시 집중해서 들었던 것 같아요.
실제로 문제를 하나 풀면서 강의를 해 주셨는데, 다이나믹 프로그래밍(Dynamic programming)에 대한 문제를 풀었어요. LCS(Longest Common Subsequence) 문제였는데 겹치는 문자열 중 가장 긴 문자열의 길이를 구하는 문제였습니다. 다이나믹 프로그래밍은 배열을 만들어서 연산한 값을 그 배열에 넣은 뒤 참조해서 사용하는 문제로, 시간복잡도를 확실히 줄일 수 있다는 장점이 있습니다.
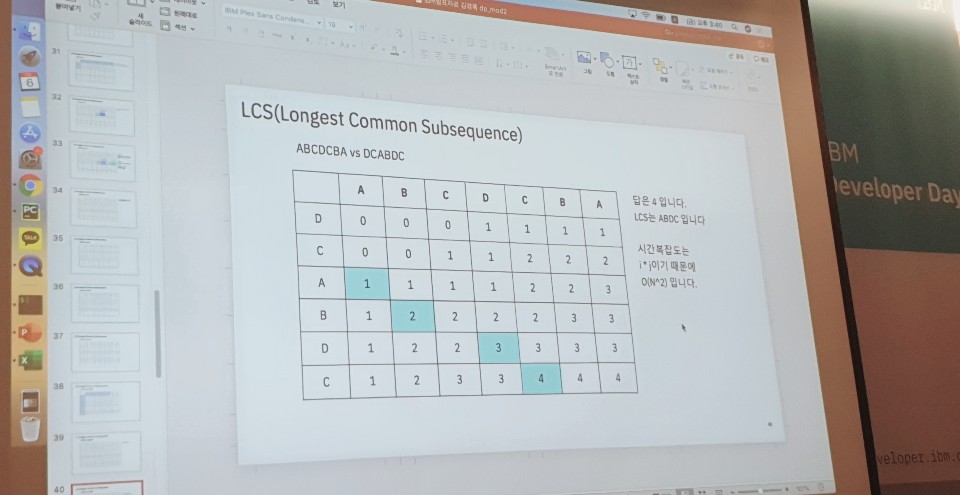
저는 이 문제에 대한 소스코드를 자바로 한 번 앉은 자리에서 짜 보았습니다.
int duplicate(String firstStr, String secondStr) {
String[] first = firstStr.split("");
String[] second = secondStr.split("");
int[][] dp = new int[first.length][second.length]
for(int i=0;i<first.length;i++) {
for(int j=0; j<second.length;j++) {
dp[i][j] = Math.max(first[i],second[j]);
if(first[i] == second[j]) dp[i][j] += 1;
}
}
return dp[first.length-1][second.length-1];
}
오픈소스 컨트리뷰터로서 성장하는 개발자 : 글로벌 커뮤니티에서는 어떻게 가능할까?
마이크로소프트 최영락님
영락님은 오픈 소스 생태계에 대한 이야기를 주로 해 주셨습니다. 과거에 플로피디스크나 USB를 사용하면서 소프트웨어를 공유하기 시작했으며 현재는 이를 온라인 상에서 더욱 활발하게 진행하고 있다는 이야기인데요. 오픈소스 생태계는 주로 Foundation(ex. Linux Foundation, Apache Foundation, Mozilla Foundation)이나 Company(ex. Google, IBM, Facebook, MS 등)에 의해서 주도되고 있다고 하셨고, 한국에서도 이러한 활동이 더욱 활발해 져야 한다고 하셨습니다.

오픈소스 생태계는 직접 만나서 협업이 이루어지는 경우보다는 멀리 떨어진 경우에서 이루어지는 경우가 많다보니, 다음과 같은 환경들이 필요합니다.
- 공유 가능한 환경
- 저장소
- 커뮤니케이션 방식
- 이슈 프로젝트 관리
- 프로젝트 상태를 알리는 환경
- CI/CD
- 문서화
- 번역
- 릴리즈 관리
- 규범 & 거버넌스
- Code of Conduct
- 여러 팀에서 관리
- 오픈소스 가치관
작고 빠른 딥러닝 그리고 Edge Computing
LG전자 양서연님

서연님은 임베디드 환경에서 딥러닝을 사용하는 환경에 대한 주제를 다루어 주셨습니다. 요즘 클라우드 컴퓨팅이 화두가 되고 있지만, 클라우드 컴퓨팅이 맞지 않는 분야도 있으며(ex. 자율 주행, 네트워크가 끊어지면 사고날 수 있음), latency 이슈도 있기 때문에, 간단하고 빠른 연산을 할 때는 클라우드보다는 Edge Computing이 더 적합하다는 설명을 해 주셨습니다.
Model Compression과 Compact Networks Design하는 방법들에 대해 소개를 해 주셨습니다. Model Compression은 원래 되자인 되어 있는 모델을 압축하는 방식으로 Prunning, Quantization, Tensor Factorization 등이 포함이 됩니다. Compact Networks Design은 디자인 하는 과정에서 연산량을 낮추고 가볍게 만드는 기법을 말하는 것으로 Residual Connection, Bottleneck Convolution, Depthwise Separable Convolution 등이 여기에 속하게 됩니다. 딥러닝에 대한 기본지식이 없다보니 이해하는 데에 조금 어려움은 있었던 것 같습니다.
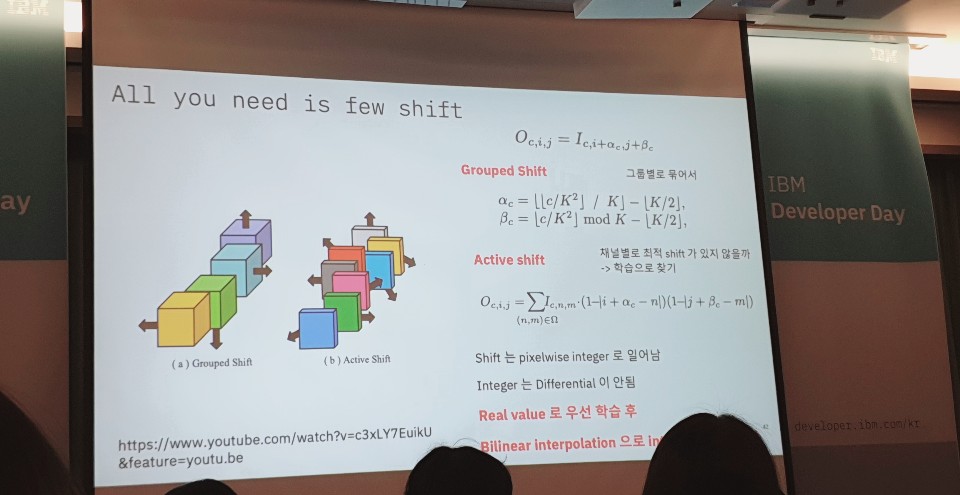
이렇게 6개의 세션 발표를 들었고, 저에게는 정말 유익했던 시간이었던 것 같습니다. 앞으로 개발자로 성장하는데 많은 생각을 하게 되었던 것 같아요. 내년에도 참가할 의향이 있으며, 관심있으신 분들은 기회를 놓치지 마시고 꼭 가보기를 권장하면서 오늘 포스팅은 여기서 마치도록 할께요